配配新电脑
之前就听说实验室可以给新生配台电脑,最近感觉手里用了三年半的拯救者Y7000P大限将至:初步感觉是机械硬盘或者固态上了年头,打算直接搞一台新电脑
甘Sir说买电脑的额度是2w左右,大喜过望得搞了一台1.8w 的 2022拯救者Y9000K,做了一把冤大头
个人比较喜欢拯救者工业化和商务的风格,以及内部的细节做工。之前拆Y7000P的时候就对内存屏蔽罩和散热布局好感拉满,对比我之前的暗影精灵4属实差别很大。暗影精灵4因为我之前拆机时候的静电搞坏了一个内存槽。然后电池还因为bios的问题鼓包过。导致我从此就成了惠普黑。
Y9000K 比隔壁同配置的枪神6贵了1k,不过枪神6过于电竞风格所以不太感冒
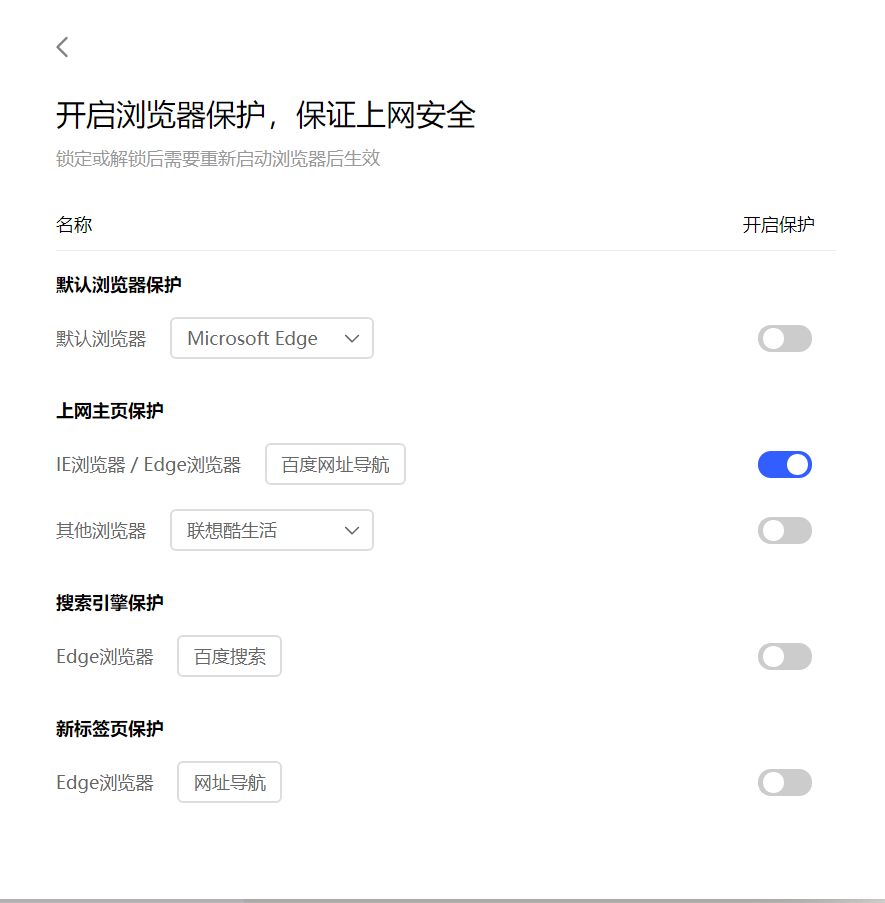
值得一提的是联想近几年在流氓软件的道路上越走越远,预装了一个辣鸡联想浏览器以及软件管家之类的流氓产品,电脑管家和傻逼百度串通改edge主页
CPU 是 i7-12800HX, 2.3GHz
12代 intel alder lake 架构
32GB内存,自带硬盘 1TB
后来自己加了一条 1TB 的 samsung 980 PRO
硬盘的 S.M.A.R.T. 数据显示电脑在买回来的时候通电时间就有一百多个小时,unsafe shutdowns 20次
作为对比,新买的 980 PRO 通电时间4小时,unsafe shutdowns 0次
emmm,不知道之前被用来干啥了。。。
用 samsung magican 跑了一发自带硬盘 benchmark :

对比一下 980 PRO 的 benchmark 结果:

emmmm,随机读写差了将近三倍。。。
搞得我都想把 980 PRO 弄成系统盘了
想想还是不折腾了